Statistical learning knowledge repository
17 Sep 2020This is a collection of my notes on various topics of statistical learning. It is intended as a knowledge repository for some of the unexpected discoveries, less-talked-about connections, and under-the-hood concepts for statistical learning. It’s a work in progress that I will periodically update.
Ridge regularization
Relationship between OLS, Ridge regression, and PCA
Simple yet elegant relationships between OLS estimates, ridge estimates and PCA can be found through the lens of spectral decomposition. We see these relationships through Exercise 8.8.1 of MA1.
Set-up
Given the following regression model:
\[\mathbf{y}=\mathbf{X} \boldsymbol{\beta}+\mu \mathbf{1}+\mathbf{u}, \quad \mathbf{u} \sim N_{\mathrm{n}}\left(\mathbf{0}, \sigma^{2} \mathbf{I}\right),\]consider the columns of $\mathbf{X}$ have been standardized to have mean 0 and variance 1. Then the ridge estimate of $\boldsymbol{\beta}$ is
\[\boldsymbol{\beta}^* = (\mathbf{X}^{\top} \mathbf{X} + \lambda \mathbf{I})^{-1} \mathbf{X}^{\top} \mathbf{y}\]where for given $\mathbf{X}$, $\lambda \ge 0$ is a small fixed ridge regularization parameter. Note that when $\lambda = 0$, it is just the OLS formulation. Also, consider the spectral decomposition of the var-cov matrix $\mathbf{X}^{\top} \mathbf{X} = \mathbf{G} \mathbf{L} \mathbf{G}^{\top}$. Let $\mathbf{W} = \mathbf{X}\mathbf{G}$ be the principal component transformation of the original data matrix.
Result 1.1
If $\boldsymbol{\alpha} = \mathbf{G}^{\top}\boldsymbol{\beta}$ represents the parameter vector of principal components, then we can show that the ridge estimates $\boldsymbol{\alpha}^*$ can be obtained from OLS estimates $\hat{\boldsymbol{\alpha}}$ by simply scaling them with the ridge regularization parameter:
\[\alpha_{i}^{*}=\frac{l_{i}}{l_{i}+\lambda} \hat{\alpha}_{i}, \quad i=1, \ldots, p.\]This result shows us two important insights:
- For PC-transformed data, we can obtain the ridge estimates through a simple element-wise scaling of the OLS estimates.
- The shrinking effect of ridge regularization depends on both $\lambda$ and eigenvalues of the corresponding PC:
- Larger $\lambda$ corresponds to heavier shrinking for every parameter.
- However, given the same $\lambda$, principal components corresponding to larger eigenvalues receive the least shrinking.
To demonstrate the two shrinking effects, I plotted the percentage shrunken ($1- l_{i}/(l_{i}+\lambda)$) as a function of the ordered principal components as well as the value of the ridge regularization parameter. The two shrinking effects are clearly visible from this figure.
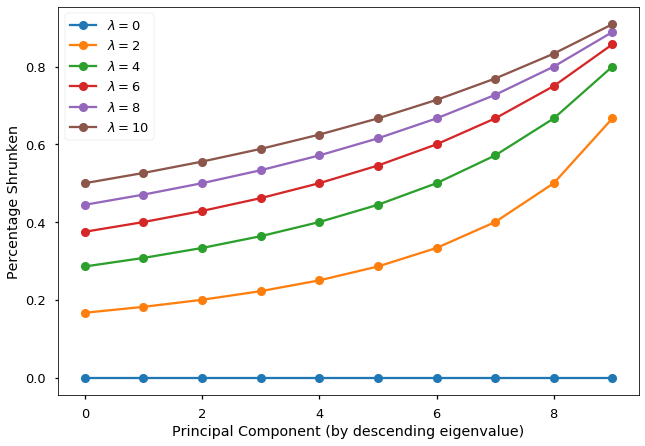
Proof of Result 1.1:
Since $\boldsymbol{\alpha} = \mathbf{G}^{\top}\boldsymbol{\beta}$ and $\mathbf{W} = \mathbf{X}\mathbf{G}$, then $$ \begin{align*} \boldsymbol{\alpha}^* &= (\mathbf{W}^{\top}\mathbf{W} + \lambda \mathbf{I})^{-1} \mathbf{W}^{\top}\mathbf{y} \\ &= (\Lambda + \lambda \mathbf{I})^{-1} \mathbf{W}^{\top}\mathbf{y} \\ &= \operatorname{diag}((l_{i} + \lambda)^{-1}) \mathbf{W}^{\top}\mathbf{y}, \quad i=1, \ldots, p. \end{align*} $$ Hence $$ \alpha^*_{i} = (l_i + \lambda)^{-1}\mathbf{w}^{\top}_{(i)}\mathbf{y} \,, $$ for $i=1, \ldots, p$, where $\mathbf{w}_{(i)}$ is the $i$th column of $\mathbf{W}$. Since $$ \begin{align*} \hat{\boldsymbol{\alpha}} &= (\mathbf{W}^{\top}\mathbf{W})^{-1} \mathbf{W}^{\top}\mathbf{y} \\ &= \operatorname{diag}(l_{i}^{-1}) \mathbf{W}^{\top}\mathbf{y}, \quad i=1, \ldots, p. \end{align*} $$ We have $$ \hat{\alpha}_{i} = l_i^{-1}\mathbf{w}^{\top}_{(i)}\mathbf{y} \,, $$ for $i=1, \ldots, p$. Therefore, by comparing the two estimate expressions, we have the result $$ \alpha_{i}^{*}=\frac{l_{i}}{l_{i}+\lambda} \hat{\alpha}_{i}, \quad i=1, \ldots, p. \blacksquare $$Result 1.2
It follows from Result 1.1 that we can establish a direct link between the OLS estimate $\hat{\boldsymbol{\beta}}$ and the ridge estimate $\boldsymbol{\beta}^*$ through spectral decomposition of the var-cov matrix. Specifically, we have
\[\boldsymbol{\beta}^{*}=\mathbf{G D G}^{\top} \hat{\boldsymbol{\beta}}, \quad \text { where } \mathbf{D}=\operatorname{diag}\left(\frac{l_{i}}{l_{i}+k} \right),\]for $i=1, \ldots, p$.
Proof of Result 1.2:
Since $\alpha_{i}^{*}=\frac{l_{i}}{l_{i}+\lambda} \hat{\alpha}_{i}$, for $i=1, \ldots, p$, and $\hat{\boldsymbol{\alpha}} = \mathbf{G}^{\top}\hat{\boldsymbol{\beta}}$, then $$ \boldsymbol{\alpha}^{*} = \operatorname{diag}(l_{i}/(l_{i}+k)) \mathbf{G}^{\top}\hat{\boldsymbol{\beta}} \,, $$ by writing in matrix form. Also, since $$ \boldsymbol{\alpha}^* = \mathbf{G}^{\top}\boldsymbol{\beta}^* $$ where $\boldsymbol{\beta}^*$ is the ridge estimate of $\boldsymbol{\beta}$, then we have $$ \begin{align*} \mathbf{G}^{\top}\boldsymbol{\beta}^* &= \operatorname{diag}(l_{i}/(l_{i}+k)) \mathbf{G}^{\top}\hat{\boldsymbol{\beta}} \\ \boldsymbol{\beta}^* &= \mathbf{G} \operatorname{diag}(l_{i}/(l_{i}+k)) \mathbf{G}^{\top}\hat{\boldsymbol{\beta}} \\ &= \mathbf{G D G}^{\top} \hat{\boldsymbol{\beta}} \end{align*} $$ where $\mathbf{D}=\operatorname{diag}\left(\frac{l_{i}}{l_{i}+k} \right)$, for $i=1, \ldots, p$. $\blacksquare$Result 1.3
One measure of the quality of the estimators $\boldsymbol{\beta}^*$ is the trace mean square error (MSE):
\[\begin{align*} \phi(\lambda) &= \operatorname{tr} E[(\boldsymbol{\beta}^* - \boldsymbol{\beta})(\boldsymbol{\beta}^* - \boldsymbol{\beta})^{\top}] \\ &= \sum_{i=1}^{p} E[(\beta_{i}^* - \beta_{i})^2] \,. \end{align*}\]Now, from the previous two results, we can show that the trace MSE of the ridge estimates can be decomposed into two parts: variance and bias, and obtain an explicit formula for them. The availability of the exact formula for MSE allows things like regularization path to be computed easily.
Specifically, we have
\[\phi(\lambda) = \gamma_1(\lambda) + \gamma_2(\lambda)\]where the first component is the sum of variances:
\[\gamma_1(\lambda) = \sum_{i=1}^{p} V(\beta_{i}^*) = \sigma^2 \sum_{i=1}^{p} \frac{l_i}{(l_i + \lambda)^2} \,,\]and the second component is the sum of squared biases:
\[\gamma_2(\lambda) = \sum_{i=1}^{p} (E[\beta_{i}^* - \beta_{i}])^2 = \lambda^2 \sum_{i=1}^{p} \frac{\alpha_i^2}{(l_i + \lambda)^2} \,.\]Proof of Result 1.3:
First let's look at the sum of variances. We start by writing out the expression for the variance of the ridge estimates: $$ \begin{align*} V(\boldsymbol{\beta}^*) &= \mathbf{GDG}^{\top} V(\hat{\boldsymbol{\beta}}) \mathbf{GDG}^{\top} \\ &= \mathbf{GDG}^{\top} \sigma^2 \mathbf{X^{\top}X}^{-1} \mathbf{GDG}^{\top} \\ &= \sigma^2 \mathbf{GDG}^{\top} (\mathbf{GLG})^{-1} \mathbf{GDG}^{\top} \\ &= \sigma^2 \mathbf{GD} L^{-1} \mathbf{DG}^{\top} \\ &= \sigma^2 \mathbf{G} \operatorname{diag}(l_i/(l_i + \lambda)^2) \mathbf{G}^{\top} \,, \quad i=1, \ldots, p. \end{align*} $$ Hence, by extracting out the variances from the diagonal, we obtain the first expression: $$ \begin{align*} \gamma_1(\lambda) &= \sum_{i=1}^{p} V(\beta_{i}^*) \\ &= \operatorname{tr} V(\boldsymbol{\beta}^*) \\ &= \sigma^2 \operatorname{tr}(\operatorname{diag}(l_i/(l_i + \lambda)^2) \mathbf{G}^{\top} \mathbf{G}) \\ &= \sigma^2 \sum_{i=1}^{p} \frac{l_i}{(l_i + \lambda)^2} \,. \end{align*} $$ Now let's look at the bias term. We write it in matrix form to see that: $$ \begin{align*} \gamma_2(\lambda) &= \sum_{i=1}^{p} (E[\beta_{i}^* - \beta_{i}])^2 \\ &= (E[\boldsymbol{\beta}^*] - \boldsymbol{\beta})^{\top}(E[\boldsymbol{\beta}^*] - \boldsymbol{\beta}) \\ &= (\mathbf{GDG}^{\top}\boldsymbol{\beta} - \boldsymbol{\beta})^{\top}(\mathbf{GDG}^{\top}\boldsymbol{\beta} - \boldsymbol{\beta}) \\ &= \mathbf{B}^{\top}\mathbf{GD}^2\mathbf{G}^{\top}\boldsymbol{\beta} - 2\boldsymbol{\beta}^{\top}\mathbf{GDG^{\top}}\boldsymbol{\beta} + \boldsymbol{\beta}^{\top}\boldsymbol{\beta} \\ &= \boldsymbol{\alpha}^{\top}\mathbf{D}^2\boldsymbol{\alpha} - 2\boldsymbol{\alpha}^{\top}\mathbf{D}\boldsymbol{\alpha} + \boldsymbol{\alpha}^{\top}\mathbf{G^{\top}G}\boldsymbol{\alpha} \\ &= \boldsymbol{\alpha}^{\top} (\mathbf{D}^2 - 2\mathbf{D} + 1) \boldsymbol{\alpha} \\ &= \boldsymbol{\alpha}^{\top} \operatorname{diag}(\lambda^2/(l_i + \lambda)^2) \boldsymbol{\alpha} \\ &= \lambda^2 \sum_{i=1}^{p}(\alpha_{i}^2/(l_i + \lambda)^2) \,. \end{align*} $$ Combining the two gamma terms completes the proof. $\blacksquare$Result 1.4
This is a quick but revealing result that follows from Result 1.3. Taking a partial derivative of the trace MSE function with respect to $\lambda$ and take $\lambda = 0$, we get
\[\frac{\partial{\phi(\lambda)}}{\partial{\lambda}} = -2 \sigma^2 \sum_{i=1}^{p} 1/l_i^2 \,.\]Notice that the gradient of the trace MSE function is negative when $\lambda$ is 0. This tells us two things:
- We can reduce the trace MSE by taking a non-zero $\lambda$ value. In particular, we are trading a bit of bias for a reduction in variance as the variance function ($\gamma_1$) is monotonically decreasing in $\lambda$. However, we need to find the right balance between variance and bias so that the overall trace MSE is minimized.
- The reduction in trace MSE by ridge regularization is higher when some $l_i$s are small. That is, when there is considerable collinearity among the predictors, ridge regularization can achieve much smaller trace MSE than OLS.
Visualization
Using the sklearn.metrics.make_regression function, I generated a noisy regression data set with 50 samples and 10 features. However, most of the variances (in PCA sense) are explained by 5 of those 10 features, i.e. last 5 eigenvalues are relatively small. Here are the regularization path and the coefficient error plot.
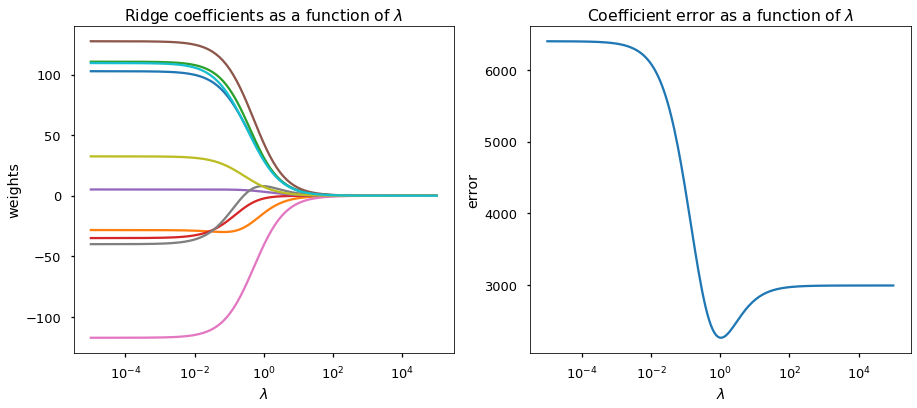
From the figure, we can clearly see that
- Increasing $\lambda$ shrinks every coefficient towards 0.
- OLS procedure (left-hand side of both figures) produces erroneous (and with a large variance) estimate. the estimator MSE is significantly larger than that of the ridge regression.
- An optimal $\lambda$ is found at around 1 where the MSE of ridge estimated coefficients is minimized.
- On the other hand, $\lambda$ values larger and smaller than 1 are suboptimal as they lead to over-regularization and under-regularization in this case.
Click here for the script to generate the above plot, credit to scikit-learn.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_regression
from sklearn.linear_model import Ridge
from sklearn.metrics import mean_squared_error
clf = Ridge()
X, y, w = make_regression(n_samples=50, n_features=10, coef=True,
random_state=1, noise=50,
effective_rank=5)
coefs = []
errors = []
lambdas = np.logspace(-5, 5, 200)
# Train the model with different regularisation strengths
for a in lambdas:
clf.set_params(alpha=a)
clf.fit(X, y)
coefs.append(clf.coef_)
errors.append(mean_squared_error(clf.coef_, w))
# Display results
with plt.style.context('seaborn-talk'):
plt.figure(figsize=(15, 6))
plt.subplot(121)
ax = plt.gca()
ax.plot(lambdas, coefs)
ax.set_xscale('log')
plt.xlabel('$\lambda$')
plt.ylabel('weights')
plt.title('Ridge coefficients as a function of $\lambda$')
plt.axis('tight')
plt.subplot(122)
ax = plt.gca()
ax.plot(lambdas, errors)
ax.set_xscale('log')
plt.xlabel('$\lambda$')
plt.ylabel('error')
plt.title('Coefficient error as a function of $\lambda$')
plt.axis('tight')
plt.show()
References
-
Mardia, K. V., Kent, J. T., & Bibby, J. M. Multivariate Analysis. 1979. Probability and mathematical statistics. Academic Press Inc. ↩